이전 실습 : [AWS]Analytics on AWS 워크샵 실습하기(2)
3. AWS Glue를 이용한 데이터 변환
이번에는 AWS Glue ETL을 사용하여 데이터를 처리하고 결과를 다시 S3에 저장해보도록 합시다!
1. Glue 개발엔드포인트 생성
PySpark를 사용하여 Glue ETL 스크립트를 대화식으로 개발하기 위해 AWS Glue Dev Endpoint를 생성합니다.
Glue 개발 엔드포인트 콘솔로 이동하여 '엔드포인드 추가'를 클릭합니다

개발 엔드포인트 설정은 아래와 같이 진행합니다.
DPU를 2로 하게 되면 이 실습을 실행하는데 드는 비용이 절감됩니다.
다음을 누릅니다.

네트워킹은 '네트워킹 정보 건너뛰기' 그대로 유지하고 다음으로 넘어갑니다.
퍼플릭 키도 마찬가지로 넘어갑니다.
그리고 마침을 누르면 엔드포인트가 생성됩니다.
가이드에 따르면 새로운 Glue 개발 엔드포인트가 가동되는데 몇 분(6-10 분)이 걸립니다. 상태가 PROVISIONING에서 READY로 변경되는 것을 볼 수 있습니다.
다음 단계로 이동하기 전에 이 단계가 완료 될 때까지 기다려야합니다.

이제 다음 단계로 갈 수 있게 되었습니다!
2. Glue 개발 엔드포인트용 SageMaker 노트북 (Jupyter) 생성
이제 노트북 콘솔로 이동합니다.
SageMaker 노트북 탭에 가서 SageMaker 노트북 생성을 누릅니다.

노트북 생성 및 구성을 다음과 같이 진행합니다. 노트북 생성을 누르고 '시작하는 중'에서 '준비'로 변경 될 때까지 기다립니다. 4~5분 정도 소요됩니다. 준비 상태가 되었으면 다음으로 넘어가겠습니다.

3. Jupyter 노트북 실행
위의 파일을 먼저 다운 받습니다
노트북 콘솔에서 aws-glue-AnalyticsworkshopNotebook 클릭하고 노트북 열기를 누릅니다.

위 화면 우측에 new 탭 옆에 upload를 클릭해 다운 받았던 ipynb 파일을 업로드합니다.

이 노트북을 열었을 때 우측 상단에 Sparkmagic(PySpark)가 표시되어 있는지 확인합니다. Jupyter가 이 노트북에서 코드 블록을 실행하는데 사용할 커널의 이름입니다.
이제 노트북 지침을 따라 진행하면 됩니다.
- 중요한 Glue 개념을 설명하는 지침을 읽고 이해합니다.
- 노트북의 내용을 실행합니다. (하단의 yourname-analytics-workshop-bucket는 적절한 경로로 변경합니다.)->18번째 코드
ETL 스크립트가 성공적으로 실행되면 콘솔로 돌아갑니다.
yourname-analytics-workshop-bucket > data로 들어갑니다.
processed-data 폴더를 엽니다. .parquet 파일들이 폴더에 생성 되었는지 확인합니다.

이제 데이터를 변환 했으므로 Amazon Athena를 사용하여 데이터를 쿼리할 수 있습니다. Glue 또는 Amazon EMR을 사용하여 데이터를 추가로 변환/집계 할 수도 있습니다.
4. AWS Glue Studio 이용한 데이터 변환
AWS Glue Studio는 AWS Glue에서 추출, 변환 및 로드(ETL) 작업을 쉽게 생성, 실행 및 모니터링 할 수 있는 새로운 그래픽 인터페이스 입니다. 데이터 변환 워크플로우를 시각적으로 구성하고 AWS Glue의 Apache Spark 기반 서버리스 ETL 엔진에서 원활하게 실행할 수 있습니다. 동일한 ETL 프로세스를 AWS Glue Studio로 수행해보겠습니다.
우선 Glue Studio 콘솔로 이동합니다. 좌측 매뉴 확장을 눌러 jobs에 들어가 'Visual with a blank canvas'를 선택하고 'create'를 누릅니다.

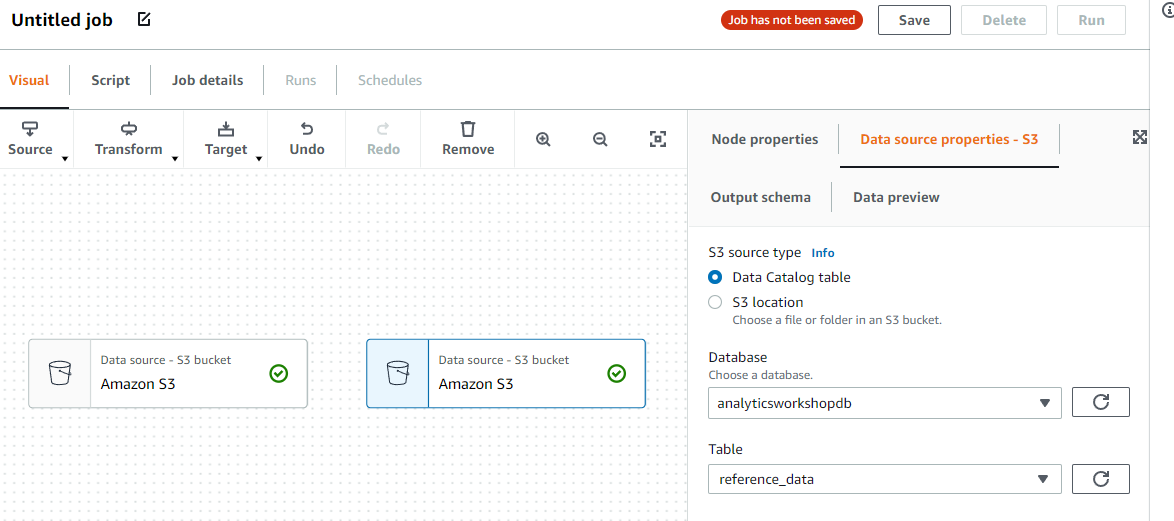
좌측 Source를 클릭하고 Amazon S3를 선택합니다. 그리고 오른쪽 Data source properties - S3 탭을 선택합니다.

그리고 Data source properties - S3 설정을 다음과 같이 진행합니다.

이제 동일한 단계를 반복하여 S3에서 reference_data를 추가합니다. 위의 테이블 값만 reference_data로 바꾸면 됩니다.
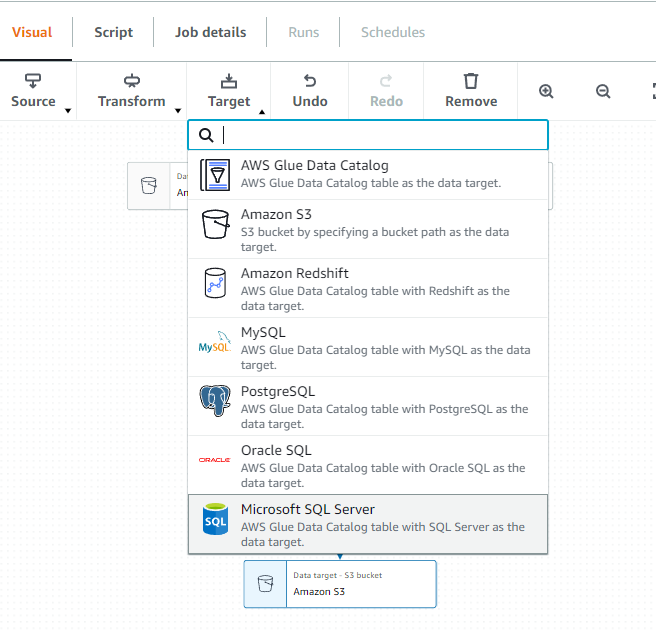
그리고 Canvas 에서 임의 노드 중 하나를 선택합니다. 전 왼쪽을 선택했습니다.
Transforn 클릭 후 join을 선택합니다.

그런 다음 Transform - Join 노드를 클릭하고 오른쪽 구성 창에서 Node properties을 클릭하고 드롭다운 목록을 선택 후 아래 스크린 샷에 표시된대로 모든 S3 데이터 원본을 확인합니다.

그리고 Transform탭을 선택하고 Add condition을 누릅니다. 그리고 track_id를 조인 열로 선택합니다.

이제는 join을 선택한 상태에서 좌측 Transform을 클릭하고 ApplyMapping을 선택합니다. 그럼 시각적 다이어그램이 표시될 것입니다.

사용하지 않는 컬럼을 삭제하고 다음 열에 대한 새 데이터 유형을 매핑합니다.
drop Columns
.track_id
parition_0
parition_1
parition_2
parition_3
Data Type 변경
track_id string
캔버스의 Transforn - ApplyMapping을 선택하고, Target에서 Amazon S3를 클릭합니다.
Data target properties - S3 에서 다음과 같이 입력 합니다.
주소는 s3://yourname-analytics-workshop-bucket/data/processed-data2/ 로 합니다.


그리고 'Job details'를 클릭해서 다음과 같은 옵션을 적용하고 Save를 클릭합니다.
- Name: AnalyticsOnAWS-GlueStudio
- IAM Role: AnalyticsWorkshopGlueRole
- Number of workers: 2
- Job bookmark: Disable
- Number of retries: 1
- Job timeout (minutes): 10
- 나머지는 기본값으로 둡니다.

Save를 클릭하면 "Successfully created job" 가 표시됩니다. 화면 오른쪽 상단의 Run을 클릭하여 ETL 작업을 시작합니다. 그리고 바로 "Successfully started job" 이 표시되면 Run Details를 클릭하여 ETL 작업을 모니터할 수 있습니다.
Glue Studio에서 생성 한 Pyspark 코드를 확인 할 수 있습니다. 필요한 경우에는 다른 용도로 이 코드를 재사용 할 수 있습니다.

그 외 비슷한 방법으로 Glue DataBrew가 있습니다. AWS Glue DataBrew는 데이터 분석가와 데이터 과학자가 데이터를 정리하고 정규화하여 분석 및 기계 학습을 준비 할 수 있도록 해주는 새로운 시각적 데이터 준비 도구입니다. 하는 방법은 비슷하니 아래 링크를 보고 따라해보시면 좋을 것 같습니다.
Transforming Data with Glue DataBrew
다음 실습 : [AWS]Analytics on AWS 워크샵 실습하기(4)
'AWS' 카테고리의 다른 글
| [AWS]Analytics on AWS 워크샵 실습하기(5) (0) | 2022.03.31 |
|---|---|
| [AWS]Analytics on AWS 워크샵 실습하기(4) (0) | 2022.03.30 |
| [AWS]Analytics on AWS 워크샵 실습하기(2) (0) | 2022.03.30 |
| [AWS]Analytics on AWS 워크샵 실습하기(1) (0) | 2022.03.30 |
| [AWS]간단 EC2 git 연동하기 (0) | 2022.03.29 |